AWS re:Invent 2018: Get Started with Deep Learning and Computer Vision Using AWS DeepLens – AIM316
Kashif Imran and Jyothi Nookula from AWS
I wanted to attend a workshop on something I don’t normally deal with. This workshop was all about deep learning so we’re into the work of AI! The idea was to learn how to build and deploy computer vision models using the AWS DeepLens deep learning-enabled video camera. This was then extended to build a machine learning application and a model from scratch using Amazon SageMaker. I would land up with and end-to-end AI application. I felt getting into AI using computer vision as an example is a good way to “see” what is possible with AI.
You can follow along at home but would need a DeepLens camera (we did receive a discount code, I may have had an urge to get one!) https://github.com/darwaishx/deep-learning-with-deeplens-reinvent-2018
This was a well setup workshop with lots of space. I was in the walk-up line as the registration was full but after missing so many sessions last year due to a suboptimal AWS Human Queuing Service, its great this year people are able to see more. Each seat had a workstation setup with a DeepLens camera.


There were multiple parts to the workshop:
- Introduction to Deep Learning and DeepLens.
- Create and deploy object detection project to DeepLens.
- Train an object detection model using Amazon SageMaker.
- Extend DeepLens object detection project to identify people who are not wearing safety hats at construction site.
- Analyse results using IoT and CloudWatch.
Machine Learning overview
An introduction into building models and not having to use EC2 instances but rather use a platform like Amazon SageMager to do all the coordination to set up your models. Then onto an end-to-end application which will use the DeepLens camera with Rekognition.
Amazon has been working on Machine Learning for 20 years, from recommendations, Alexa, Amazon Go, and plenty more. They’ve learned its hard, particularly with real-world scenarios. They set themselves a challenge, how to get ML into the hands of every developer.
Jyothi went through the components of ML:
- data: this needs to be annotated or labelled
- pre-process: makes sure things are the same kind of thing, no bias.
- model training: input the annotated and cleaned data into the model, multiple iteration to train the model then validate it with a held back dataset.
For training a model she explained the term inference (where the magic happens). This is also also output which is the result. You pre-process the new data and then feed the image back to the trained model to get a predicted output with a probability score.
Amazon Machine Learning Stack
 Amazon has three layers to its stack:
Amazon has three layers to its stack:
Frameworks and interfaces using Deep Learning AMIs such as MXNet, TensorFlow Gluon. Above that is the Platform which is Amazon SageMaker which manages the infrastructure while giving you control to build and train your modules and manage where your data set is. On top of the platform sits the application services, these are Amazon services like Rekognition, Transcribe, Translate, Polly, Comprehend and Lex. This is to make it simple so you can use an API to interact with the machine learning platform below.
DeepLens

DeepLens sits next to all three stacks and is an educational tool to help developers use machine learning with hands-on experience. This was an interesting take, I hadn’t realised it was an “educational device”. I thought it would also be pitched at more than educational needs and be kind of production ready.
Hardware wise, its a camera with an Intel Atom processor inside with a Gen9 GPU built-in, runs Ubuntu with 100 GFlops performance
With the built-in GPU you can run algorithms on the device without having to go the cloud for inference. This isn’t for training which is cloud based but inference is for testing a model and doing prototyping. As this runs locally, it is also called edge computing and is managed with AWS Greengrass. Greengrass deploys a Lambda function to the DeepLens camera which takes an image, pre-processes it, interacts with the model and shows the output
Models
AWS SageMaker comes with some pre-built models as a pre-learned environment for object/face/activity detection, artistic style transfer, cat/dog detection and hotdog/not hotdog! This means so a few things you don’t even have to train a model particularly for detecting things, its already there.
Workshop
 We built a DeepLens project and could view the live camera image with a bounding box showing faces and could also view a console session showing how the data comes off the device.
We built a DeepLens project and could view the live camera image with a bounding box showing faces and could also view a console session showing how the data comes off the device.
We then learned how to train a model to detect objects. We created a SageMaker instance, and ran a object detection notebook which uses Jupyter which I hadn’t used before. Its a very useful notebook which can contain documentation and code in the same page. You can see the explanation and click on the arrow below to launch the code based on the instructions. Very visual which helped.
We then built an end-to-end app for Worker Safety.
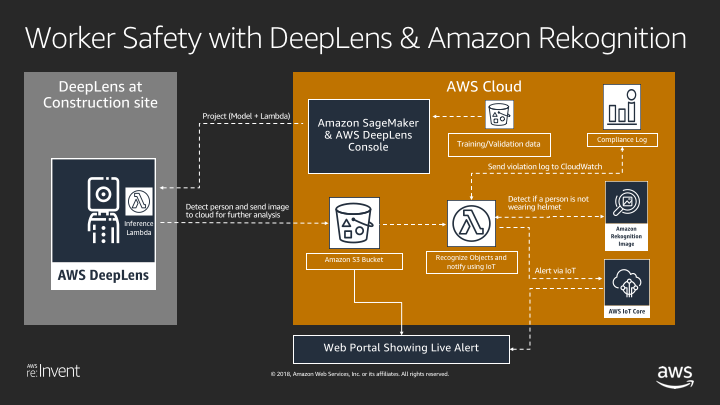
The idea was to detect people and have a Lambda function work out whether people are not wearing safety hats. This Lambda would then be deployed with Greengrass to the DeepLens Camers. As we now knew, the model would run on the camera which would then upload the photos to S3 and detect who was not wearing a hard hat which could then alert you.
Good interesting workshop, well run and we were able to follow!

Recent Comments